Transformers

Infinity Sailor
—Apr 10, 2024

Transformers
Transformer is advanced neural network architecture, that is capable of modeling complex context and meaning in the text.
Built for parallel processing. ( rnn are popular for sequential text, just processing one text at a time. )
Captures relationships and xontext between tokens.
pay attension to all the tokens in the sequence.
help build general purpose foundation models
NLP
nlp is the ability of computers to process, understand, and generate spoken and written human language and enable to automated analytics actions and interactions.
NLU : natuaral language understanding. ( sentiment analysis, summerization )
information Extraction :
Previous Neural networks good for
ANN -> Tabular data
CNN -> Image Data
RNN -> Sequencial Data
Transformers -> Sequence ( input ) to Sequence ( Output )
![]()
Transformers uses encoders and decoders.
Attention is all you need : papers released in 2017, google brain, deep learning. introduced the Self Attention.
Impact of Transformers
Revolution in the field of the NLP.
Availalble models like BERT which can be fine tuned further.
The flexible architecture of transformers gives it Multimodel Capability. text, images, etc
Acceleration of Gen AI : Previously GANs were there but they werent so practical like transformers.
Origin of the Transoformers
2000-2014 -> RNN/LSTM
2014-15, Sequence to sequece learning with neural networks.
was used to convert machine code.
its Encoder to decoder. uses LSTM.
Context vector => Encoded data which is then sent to decoder.
Not working for large input data.
Neural Machine translation by Jointly learning to align and translate.
Inpute is feed in step by step mechanism, maintaining some vector state.
Context vector
attention mechanism.
Had issues due to sequential methods. ( it used LSTM which is sequential so slow )
2017, Attention Is All You Need : paper resealed in 2017, by Google Brain.
Paper introduced self attention mechanism. removed the LSTM / RNN.
Encoders work in parrallel, which helps in working with Large dataset.
2018 - 2020 -> Vision Tranformers/alphafold-2
2022 -> chatGPT / Stable Diffusion.
Benifits of Transformers
Scalability : can be used parallely and consume large amount of data
Tranfer Learning
Multimodal Input/Output
Flexible Architecture
Integration with other Architectures like GANs ( dalle ), RL ( for agents ), CNN ( vision transformer )
Limitations of Transformers
High compution required. (GPU)
Required Data.
Data Overfitting.
Energy Consumption.
Interpretability ( whats going on inside ) [ blackbox]
Biasness/ ethical ness
Self Attention
NLP -> words -> Numbers => process is called Vectorization
OHT => one hot encoding. create matrix one to one relation.
Bow => Count how many times unique items came
Tf-IdF => each unique token is a feature and weights values by frequncy and uniqueness.
Word Embeddings => It captures semantic meaning ( static ) created once and used repetedly.
self attention is nothing but the smart word embedding or context based word embedding, it takes static word embedding and convert it to context based word embedding.
RNN
Unstructured data -> Sequential data
Structured data -> unsequential data
Rnn output loopsback as input.
Rnn can be of different types : one to one, one to many, many to one, many to many
Tokenization
splitting of phrase or sentence into smaller units called tokens and then using them as input for further text process and analytics.
word tokenization : word to word are handled but has issue with out of vocabulary words.
character tokenization : no context of sequence of the word
sub-word tokenization : a word is either split with sufix or prefix or kept same.
Tokenizer -> a program that convers the text to the tokens
this could be specific to language or domain.
its pre-built and available in libraries. GloVe, Word2Vec
Vectorization
Converting text data to equivalent numerical representation that can be consumed by machine learning algorithms. Vectorization needs to retain that content, context, and sequencing.
Position Encoding
Positional Encoding is a process of deriving the vector for each token in a sentence to represent its position in the sentence.
RNNs used to capture positional information by processing one token at a time, in sequence, to build a hidden state.
In transformers, tokens are processed parallelly so they require this positional context at the time of processing.
The dimension of the positional vector is the same as that of the embedding vector.
Attention in Transformers
Tokens in sequences have semantic relationships. Self-attention is used to understand the context. i.e. I ordered books from amazon and they are not so good. Here, Humans can understand what "they" is referring to but how will the program know?
Self-Attention is computed for each token in the input.
.png)
Multi Head Self-Attention
Used to focus on different relationships in the same sentence.
Masked Attention.
for masked attention only the tokens before this token is considered.
Encoder
Can handle large amounts of data at once making this scalable
It encodes the input text.
The encoder converts a given set of tokens in a sentence into equivalent vectors called hidden states or context. This vectors capture the semantics and relationships between the tokens in the sentence.
![]()
There could be more encoder layers with same input and output dimentions. each encoder output is sent to next layer to the Final encoder output.
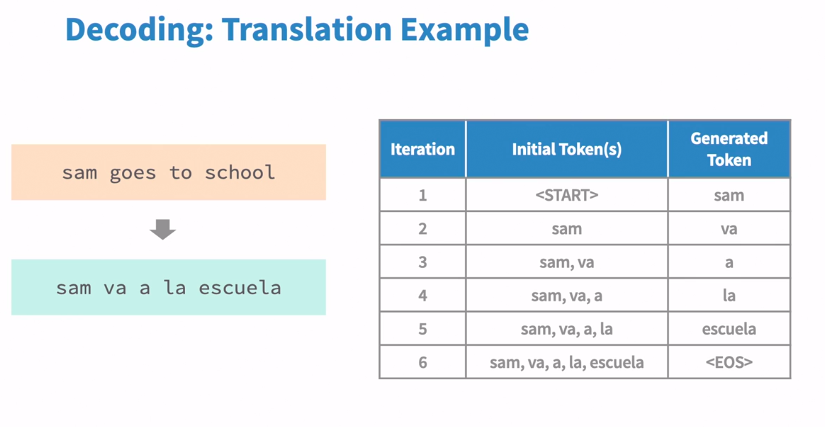
Encoder Processing considering a example , sam goes to school.
![]()
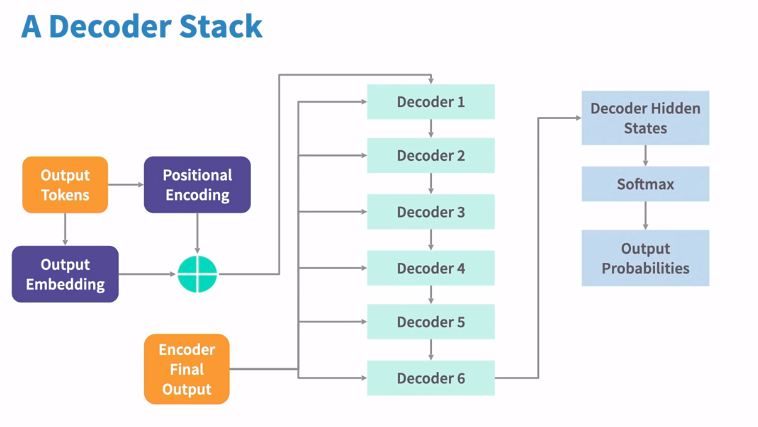
Decoder
The decoder uses the encoders hidden states to iteratively generate a sequence of output tokens, one at a time. the form of output depends on the use case.
![]()
In decoder stack there are 6 decoder layers, Hidden state of encoder layer is available for each of the decoder layer.
As it can be seen in example, each token is generated based on last tokens.